Gretel Releases World’s Largest Synthetic Open-Source Text-to-SQ
Spain, May 08, 2024 — In the ever-evolving landscape of Large Language Models (LLMs) and artificial intelligence (AI), data quality has emerged as a critical factor. Recent breakthroughs in models like Falcon, Phi-1.5, Phi-2, Aya, and Gemini underscore the importance of high-quality training data. Andrew Ng aptly describes this as “the discipline of systematically engineering the data needed to build a successful AI system.”
At Gretel, they recognize that data quality is the bedrock upon which powerful AI models are built. Our commitment to advancing data-centric AI led them to create a groundbreaking solution: the world’s largest synthetic open-source Text-to-SQL dataset.
The Power of Synthetic Data
Phi-2: The Surprising Power of Small Language Models
Phi-2, a small yet potent language model, highlights the significance of training data quality. Theirs approach goes beyond conventional wisdom, incorporating synthetic datasets specifically designed to teach the model common sense reasoning and general knowledge. These synthetic datasets cover diverse topics, including science, daily activities, and theory of mind.
Aya Model: Bridging Reasoning and Translation
The Aya Model further extends the utility of synthetic data generation. By combining translation with synthetic data, they promote reasoning, code generation, and algorithmic skills. Theirs commitment to data quality remains unwavering, as they explore optimal dataset distributions for pre-training.
Gemini: Multimodal Excellence
Gemini, a family of highly capable multimodal models, reinforces the importance of data quality. Theirs sources include vendor-created data, third-party licensed sources, and synthetic approaches. As the AI landscape evolves, data quality remains a cornerstone.
The Challenge of Poor Data Quality
While the adage “garbage in, garbage out” has long been known to data practitioners, the reality is stark. Poor data quality plagues ML applications, making it challenging to harness high-quality data. Data teams spend up to 80% of their time cleaning and improving data, exacerbating the problem.
According to the dbt Labs 2024 State of Analytics Engineering, 57% of professionals now consider poor data quality a predominant issue, up from 41% in 2022.
Gretel’s Solution: Pioneering High-Quality Synthetic Data
At Gretel, they believe in a better way. They address data quality head-on by empowering organizations to generate high-quality synthetic data. Theirs approach allows teams to create data from scratch or augment existing data while safeguarding privacy and security.
Introducing the Gretel Text-to-SQL Dataset
Today, they proudly announce the release of the gretelai/synthetic_text_to_sql dataset. This purely synthetic Text-to-SQL dataset, available on Hugging Face, represents a significant leap forward. Here’s what you need to know:
- Dataset Overview:
- 105,851 records, divided into 100,000 training and 5,851 test records.
- Approximately 23 million total tokens, including around 12 million SQL tokens.
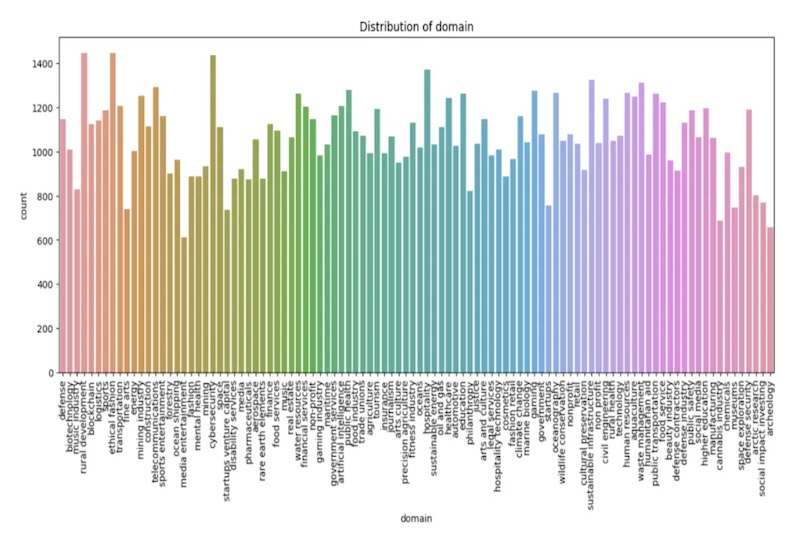
- Coverage across 100 distinct domains and verticals.
Leveraging AI Text-to-SQL for Business Success
For WCHAM members seeking to enhance their businesses, AI-powered Text-to-SQL offers exciting possibilities:
- Automated Query Generation: Use AI to generate SQL queries from natural language text. This streamlines data retrieval and analysis, saving time and effort.
- Enhanced Decision-Making: Leverage Text-to-SQL models to extract insights from complex databases. Make informed decisions based on accurate, real-time information.
- Data-Driven Marketing: Optimize marketing campaigns by querying databases directly. Understand customer behavior, preferences, and trends effortlessly.
- Efficient Reporting: Generate dynamic reports by converting natural language questions into SQL queries. Stay ahead with up-to-date business intelligence.
In summary, the gretelai/synthetic_text_to_sql dataset opens doors to improved AI training, better decision-making, and data-driven success. As WCHAM embraces this innovation, we encourage members to explore AI Text-to-SQL and unlock its potential for their businesses.
Let’s build a future where data quality fuels AI excellence!
Reference:
Gretel Blog: Synthetic Text-to-SQL Dataset
CIO First: Gretel Releases World’s Largest Open Source Text-to-SQL Dataset
Stories in AI: The Largest Text-to-SQL Dataset123″,”As of April 202

Subscribe newsletter
Check out Wilsh
